Multi-task learning loss balancing
June 29, 2020
7 mins read
Multitask learning
Multi-task artificial neural networks have several advantages over a set of single-task neural networks. Sharing of features between several tasks reduces total amount of computations required, making the final pipeline faster on the inference stage. In addition, training of several somehow related tasks can benefit from the synergistic effect and also acts as a regularization because it helps to learn more general features, hence reduce the chances of overfitting. The approach is widely used, for example, in autonomous driving vehicles and sports analysis.

Fig. 1. Tesla is using multi-task neural network as the core for the Computer Vision based perception system [1].
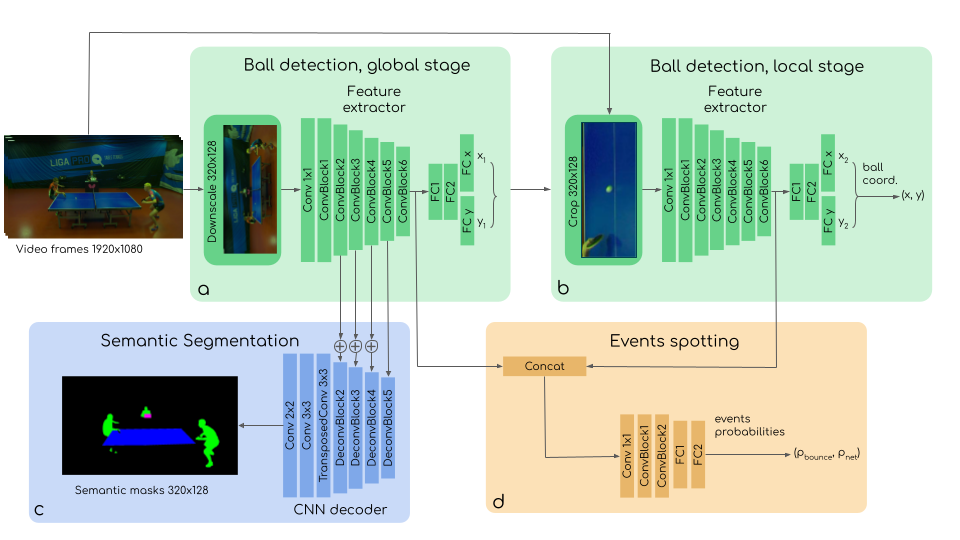
Fig. 2. TTNet: Real-time neural network video analysis of table tennis. It comprises tasks of different modalities: temporal (event spotting) and spatial (semantic segmentation, ball detection) [2].
However, there are several potential challenges to using a multi-task neural network as opposed to a set of single-task neural networks, especially during the training stage. One challenge is obtaining data that includes annotations for all tasks simultaneously in the training set. Additionally, tasks may have different complexities or importance, which can lead to imbalanced training if not addressed properly. This can result in the prediction quality for some tasks being much better than for others. Smart approaches for loss balancing may be necessary to address this issue. The post presents some approaches to resolve these issues, using the TTNet architecture for illustration. The sample architecture is selected because I’m working on the topic for quite a long time and we have prepared a CVPRw publication on it [2].
TTNet is a real-time architecture for video analysis of table tennis. It’s main purpose is providing the core information for reasoning score updates by an auto-referee system. It includes the ability to spot temporal events (like the ball bounces and net touches), as well as spatial features: semantic segmentation maps and the ball position.
Approaches
Data
Although loss balancing is more important and more complex part of multi-task neural networks training, the challenges with the data needs to be resolved as well, because success of supervised ML pipelines is greatly attributed to the data used for training.
There are several approaches to reduce cost of data for multi-task pipelines. Most of them are dealing with the fact that manual annotation may be not available for all tasks on the whole training set. In reality, it is quite common that just a subset of the data have labels for one task, and partially overlapping subset of samples is available for the other task.
- Semi-multi-task learning. The approach means training of the main backbone and some of the heads on a subset of tasks, for which the most of labeled samples are available and then training the rest of task-specific heads with frozen backbone. The approach is quite easy to implement, however, the results of the vanilla implementations may be far from the best possible quality. One of the way to improve results is iterative approach, which includes iterative finetuning of the neural networks on subset of the tasks.
- Auto-annotation. It is often the case that certain tasks in a multi-task problem are easier to obtain annotations for, while others may be more costly or time-consuming to label. In addition, some tasks may be trained to a reasonably good state with imperfect annotation. For example, the data for events for TTNet, like the ball bounces, does not allow compromises on quality, because the events are essential for score reasoning. So, all of the events were annotated manually with great attention to details and double-checked. As TTNet is video-based neural network, all data types need to be available for all of the frames. Given there are millions of video frames in the training dataset, it makes manual annotation of semantic masks or the ball position virtually impossible. So, for that reaon, just a diverse subset of the training data was annotated with semantic masks and the ball position and the annotation for the rest of the frames was obtained by auto-annotators: single-task deep learning models, trained on the particular tasks. The quality of auto-annotations could be quite high since it is possible to use relatively heavy models for auto-annotation as there is no requirements for real-time on the auto-annotation stage.
It is worth noting that these approaches may not be applicable in all cases, and the choice of approach will depend on the specific characteristics of the data and the tasks being performed.
Loss balancing
Multi-task training requires loss aggregation. There are three main strategies:
- Scale loss to about the same range and train the whole network with uniform loss weights.
- Finetune the loss components weights manually or automatically (e.g., using Optuna) and use constant loss weights throughout training.
- Treat the loss components weights as trainable parameters and tune them automatically while training.
The first two approaches assume that the the whole training needs to be performed with the same weights for the loss components. However, in reality it is not always the optimal approach. For instance, TTNet predicts data of different modalities, and the predictions are interconnected. For example, the success of the event spotting branch is related to the success of the ball detection, as the events are predicted for frame crops around the proposed ball position. Moreover, the differences in the target data types lead to inconsistent learning paces (i.e. one of the tasks may start overfitting, while the other is still need further training). Therefore, an approach that considers the homoscedastic uncertainty of each task and incorporates the relative weights of the losses adaptively seems to be a good idea. For example, such an approach is described in [3]. It can be implemented to presents the total loss as follows:
\[L=\sum_{i=1}^{N_{loss}}\frac{L_i}{\sigma_i^2+\epsilon} + \sum_{i=1}^{N_{loss}}\log {(\sigma_i+\epsilon)}\], where \( L_i \) - individual loss components, \( N_{loss} \) - total number of loss components, \( \sigma_i \) - trainable loss components weights, \( \epsilon \) - small value for numerical stability (e.g., 1e-8).
The last term of the sum acts as a regularizer for the trivial solution elimination. Note that depending on the tasks, the term can be a sum of logarithms or a logarithm of sigma’s product ( \( \log(\prod_{i=1}^{N_{loss}}\sigma_i + \epsilon) \) ) or a combination of these two.
PyTorch model implementation may look like the following:
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self, N_loss: int, device: str = 'cuda:0'):
...
# Register loss components weights as module parameter for update during training
self.loss_w = nn.Parameter(
torch.ones(N_loss, dtype=torch.float32, requires_grad=True, device=device)
)
def forward(self, x: torch.Tensor):
preds = f(x) # Main forward pass
...
# self.loss_w needs to be called during forward computation,
# otherwise the parameter won't be updated on each optimizer step
self.loss_w = self.loss_w
# Return predictions and sigmas for usage in loss balancing
return preds, self.loss_wIn the case of TTNet training, this adaptive approach of loss components weights balancing resulted in the best metric values in most tasks and, most importantly, resulted in the best accuracy in the event spotting task, which suggests a positive effect of multi-task synergy.
| Metric | Uniform weights | Manually weighted | Adaptive loss weights |
|---|---|---|---|
| Ball position RMSE, px | 2.93 | 2.38 | 1.97 |
| Segmentation IoU | 0.938 | 0.902 | 0.928 |
| Correct events fraction | 0.966 | 0.963 | 0.970 |
References:
[1]: Andrej Karpathy. Multi-Task Learning in the Wilderness, ICML 2019