Neural network for multiclass image segmentation
September 21, 2017
3 mins read
Introduction
The main goal of the project is to train an fully convolutional neural network (encoder-decoder architecture with skip connections) for semantic segmentation of a video from a front-facing camera on a car in order to mark pixels belong to road and cars with Tensorflow (using the Cityscapes dataset).
Dataset
The Cityscapes dataset is a very famous set of images for benchmarking semantic segmentation algorithms. There are 30 classes, such as road, car, building, traffic sign, person, etc. An example image with all masks applied is depicted below:

The glorious triple-pointed star on the hood is visible in every image and actually is a kind of watermark of the dataset.
Because it is just a learning task, only two classes (roads and cars) were chosen from the Cityscapes dataset for the segmentation. All 5000 images with fine annotations were used for training. On the preprocessing step, all images were scaled down by the factor of 2 in order to speed things up during online batch preparation.
Architecture
A Fully Convolutional Network (FCN-8 Architecture developed at Berkeley, see paper ) was applied for the project. It uses the convolutional head of VGG16 pretrained on ImageNet dataset as an encoder. A decoder is used to upsample features, extracted by the VGG16 model, to the original image size. The decoder is based on transposed convolution layers. Skip connections are used to recover the spatial resolution ou upscaled image, while the encoder output represents highly generalized features with low spatial resolution.
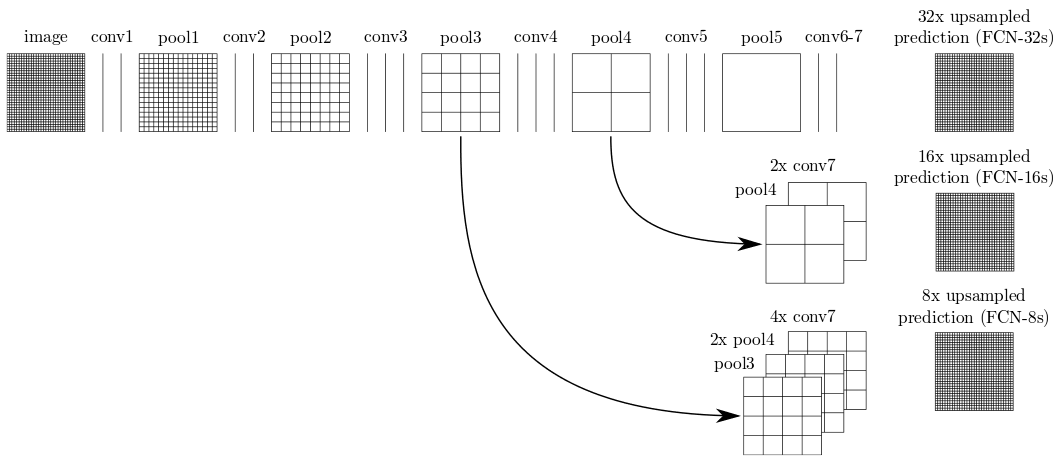
Due to fully convolutional nature of the artificial neural network, it could be applied to any image size and the image size used during training could be different from the one, used on testing or deployment stage.
Training
The training dataset was rather limited (just 5000 images). That is why, input images were treated by random contrast and brightness augmentation (as a linear function of the input image). It helps to produce reasonable predictions in difficult light conditions. The augmentation was applied online during training, so, each image for the CNN was unique to some extent. Training image size was 512x256 px.
import random
def bc_img(img, s = 1.0, m = 0.0):
img = img.astype(np.int)
img = img * s + m
img[img > 255] = 255
img[img < 0] = 0
img = img.astype(np.uint8)
return img
contr = random.uniform(0.85, 1.15) # Contrast augmentation
bright = random.randint(-45, 30) # Brightness augmentation
image = bc_img(image, contr, bright)Additionally, random Gaussian noise could be applied.
Hyperparameters were chosen by the try-and-error process. RMSProp optimizer performed better for the imageset as compared to a well-established Adam optimizer. Weights were initialized by a random normal initializer. Some benefits of L2 weights regularization were observed, therefore, it was applied in order to reduce grainy edges of masks.
One can see, that classes are unbalanced, so, there are significantly more pixels correspondent to roads, than to cars. Therefore, a weighted loss was applied with weights 2:1 (cars:roads) and some increase in the prediction quality was observed.
The CNN was trained for 30 epochs with learning rate 1e-4.
Results

It correctly do not label a cyclist as a car, but mark small partly occluded cars.

It does not have problems with recognizing a cobbled street as a road.

And the ANN is able to mark cars in different projections.