Discussion of the Lyft Perception Challenge
June 05, 2018
4 mins read
Speedup tricks
The basic prediction script was profiled with yappi multithreaded python profiler, and the profiling results gave rise to some speed up ideas.
It was observed in the training dataset, that cars and roads could not be situated on arbitrary part of the input image, but only on the central region, while the top part contains the sky and the bottom - the hood. So, the model was trained and predicts only that center part of the image. Original image was 800x600 px, while 800x320 px crops were utilized.
Images with masks should be encoded with png encoding at the final step of the pipeline. The process was parallelized with a joblib library. It is an excellent instrument for simple parallel for loops using multiprocessing or multithreading.
To increase the inference rate, one may reduce the amount of data transferred between the GPU and CPU. So, most of the postprocessing was done on a GPU, and only binary masks of desired classes were transferred back from GPU as byte tensors (3x times less volume as compared to original float32 tensor).
The whole pipeline, suggested by the competition organizers, was also optimized. It was experimentally shown that pybase64 library is faster than the standard base64 in base64 encoding. OpenCV is better for fast png encoding that PIL, which was suggested in the demo script. One may also play with the png compression rate, but it was not useful in this case. Predictions were done in a batch manner, so, it helps to utilize the whole GPU and take advantages of big VRAM storage.
A significant amount of time the prediction script spends on the model file loading, python modules import and the model preparation. In order to eliminate this lag, a client-server approach was used. A server should be started in advance and on start, it loads all the necessary things. After the server is ready, a client application can be used. Client application only sends the path to the test video as a http request and receives the predictions from the server as a json.
Each of the tricks helped to improve the FPS a little bit, but the whole program was able to reach >20 FPS rate in the testing workspace and >60 FPS on an ordinary desktop with Nvidia GTX 1080 Ti GPU. One should keep in mind that the timing result includes png and base64 encodings of the model predictions. So, the approach may be applied to real-time semantic segmentation!
Examined ideas
Besides the described pipeline, several other approaches were tested, but did not lead to better results:
-
Usage of an extra class “windows”. It was quite challenging for the neural network to correctly label pixels of transparent parts of vehicles. It seemed rather promising to predict the extra class “windows” and exclude the predictions from the “car” class. Unfortunately, the approach forces to use sigmoid as the output layer to allow classes overlap which ultimately led to overall score reduction.
-
Usage of any weights to force the CNN to pay more attention to the “car” class and deal with class imbalance. Usage of BCE element in the loss function also was not a good idea.
-
Application of Gaussian noise augmentation. The simulator produces clear images without any image-capture process related noises. Such kind of augmentation may help for real application but only slows down the training process on the simulated data.
-
Other encoders: ResNet18 was not able to achieve comparable to ResNet34 score, whereas ResNet50 heavily overfit on the train data.
-
Train separate models for “road” and “car” classes. Since the prediction rate is more than two times higher than required, we can use two models. In fact, it does not work well because the classes start to overlap. One network for both target classes works better, and in this case application of more classes may work as a kind of regularization which forces the network to understand the scene better.
Further ideas
Some further ideas for prediction results improvement:
-
The CARLA simulator provides a limited variety of cars and landscapes, so, it is possible to collect more data and virtually “overfit” to all possible scenes.
-
Use more augmentations. One may consider applying some extra augmentations to mimic lens flares and weather conditions.
-
Add some techniques to prevent overfitting: weights regularization, dropout, etc.
-
Find the best encoder architecture, experiment with the decoder blocks, or experiment with other architectures.
-
Use extra input channels with semantic masks from the previous frame. This may make masks predictions more sustainable and smooth between frames, however, it may decrease the neural network prediction speed.
Results
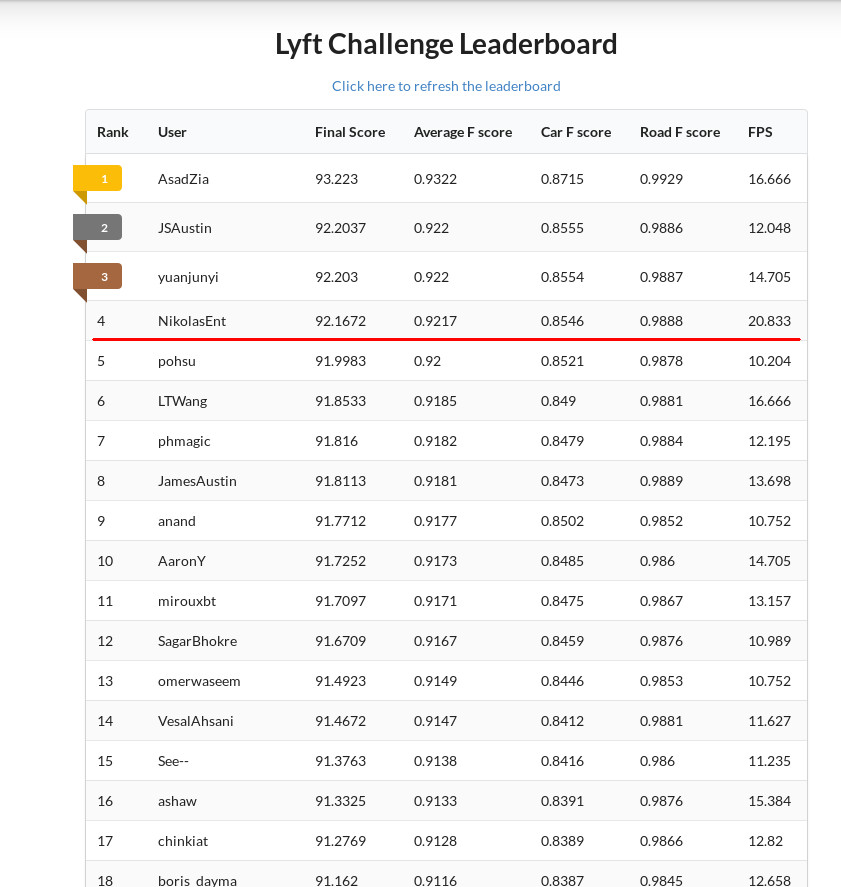
The project code is available on Github.